
EMO AI - Emote Portrait Alive
EMO AI is a portrait video generative AI that can convert your photos into videos of you speaking according to your voice.
Learn About EMO AI!
Emo AI stands for Emote Portrait Alive. It can transform portrait photos into lip-syncing talking videos. The system will automatically match fine facial expressions according to the audio and provide vivid, realistic and diverse lip-syncing effects for the portrait talking videos.
Highlight Features of EMO AI
Role Consistency
Emo AI brings every stiff photo and the person in it to life. It can perfectly match the lip movements to the audio, making it look as natural as a real person speaking. Whether it's for creating marketing videos, course explanations, or entertainment content, it can make the audience feel that the content is authentic and credible, enhancing the professionalism and attractiveness of the videos.


Generating any Video Duration
Emo won't restrict users' creativity with time limits. It can generate videos ranging from 10 seconds to 30 minutes according to users' needs. You just need to upload your audio, and then you don't have to worry about the duration at all. The AI will help you complete the subsequent task of "bringing the photo to life".
Support Multi-Language
Whether you speak Chinese, English, Spanish, or other languages, Emo AI can accurately match the lip shape and generate smooth videos. Use it for international content creation, or to create videos for users in different regions, it is completely out of the question.


Compatible with Various Photo Styles
Emo AI of TT Video is compatible with photos or images of various painting styles. Whether they are photos or images of real people, 3D works, or those from the two-dimensional world, the tool can ensure the generation of lip-syncing videos with diverse styles. It is highly suitable for UGC (User Generated Content) creators such as YouTube bloggers to add more fun to their works.
How to Use Emo AI
Step1: Upload Your Photo
Select a portrait photo with a resolution of less than 200px * 200px and click to upload it.
Step2: Upload the Audio
Select an audio file with a size of less than 30M. Audio files in formats such as MP3 and WAV are all supported.
Step3: Generating and Review
Click the "Generate" button, and then you can wait for the AI to generate an Emo Video for you within 1 minute. Then preview it. If you are satisfied with the effect, remember to download and save it.
Users' Attitudes towards Emo AI
"In the past, it took several days to do product introduction videos, just to find actors, shoot videos, and edit. Now, with Emo AI, you can upload a piece of audio and a few product pictures, and a professional-grade oral video can be generated in a few minutes! The lip matching is very natural, and customers can't tell that it was done by AI at all. The efficiency has increased by at least 80%, which is really worry-free!"

"I used the Emo AI to turn the course audio into video, and the results were amazing! My lip shape and the audio matched perfectly, and students said it looked like I recorded it myself. The best part is that I can generate hours of video content at once, and I don't have to record it over and over again. Now I have more time to focus on the course design, and the student feedback is even better."

"As a short video blogger, I have to update my content every day, and the time is very tight. Emo AI really saved me! I can directly use my voice and photos to generate videos, and I can also switch between different styles, such as reality style and two-dimensional style, which fans find very interesting. The most amazing thing is that it supports multiple languages, and I can also use it to make international content to attract more overseas fans."

"Our company often needs to produce internal training videos, which used to consume a lot of manpower just to record and edit. Now with Emo AI, we only need to upload the training recordings and photos of the instructor, and we can generate high-quality videos. The mouth shape is exactly matched, and the effect is very professional. The most important thing is that the cost is reduced by at least 50%, and the boss is very satisfied!"

"I just started my business, I had a limited budget, but I needed a high-quality promotion video. Emo AI helped a lot! I used it to generate several product introduction videos, and the effect was completely as good as that produced by a professional team. Customers said it was very professional, but they didn't expect me to do it myself. The most important thing is that the cost is almost zero, which is really suitable for the early stage of entrepreneurship!"

"Emo AI has revolutionized our advertising production process. It used to take weeks just to coordinate the actors and filming team for a commercial. Now with Emo AI, it only takes a piece of audio and a few pictures to generate a realistic oral video. What surprises me the most is that it is also compatible with different styles, such as 3D and 2D, which makes our creativity more possible."

Explore More Tools With TTVideo




The Technical Principle of EMO AI
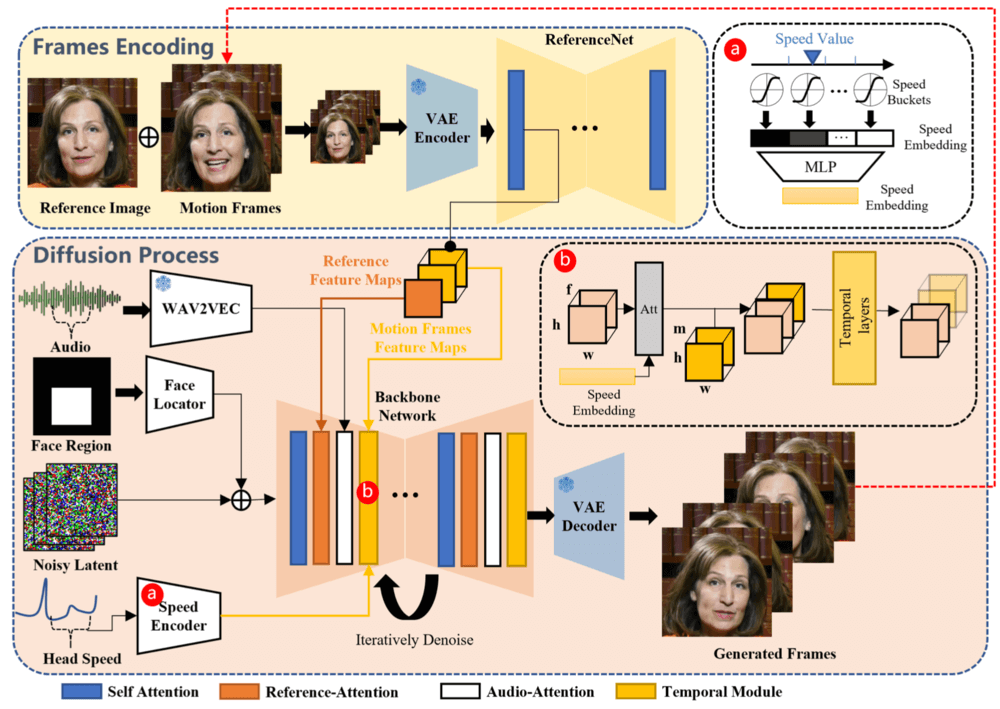
1. Input Preparation
Users are required to provide a reference image (usually a static photo of the target character) and an audio clip (such as speaking or singing voice). These materials will serve as the core inputs for generating the video.
2. Feature Extraction
The system will extract key features from the reference image through a network named ReferenceNet. The structure of ReferenceNet is similar to that of the main network, and it is specifically designed to capture detailed information from the image, ensuring that the generated character image is highly consistent with the input image.
3. Audio Processing
The audio data will be processed through a pre-trained audio encoder to extract features such as the rhythm, tone, and pronunciation of the speech. These features will be used to drive the facial expressions and head movements of the character in the video, ensuring a perfect match between the lip movements and the audio.
4. Diffusion Process
During the diffusion stage, the main network will receive multi-frame noise data and gradually transform it into consecutive video frames. This process relies on two attention mechanisms: Reference-Attention: Ensures that the generated character is consistent with the reference image. Audio-Attention: Adjusts the movements and expressions of the character according to the audio features.
5. Temporal Modules
To handle the temporal dimension and control the speed of the movements, the system has introduced temporal modules. These modules analyze the relationship between frames through the self-attention mechanism, ensuring that the dynamic effects of the video are smooth and natural, while maintaining temporal coherence.
6. Facial Positioning and Speed Control
To ensure that the generated character movements are stable and controllable, the system employs a face locator and speed layers: Face Locator: Locates the facial area through a lightweight convolutional network to ensure that the character movements are concentrated on the face. Speed Layers: Precisely controls the frequency and amplitude of the movements by embedding the head rotation speed information.
7. Training Strategy
The training process is divided into three stages: Image Pre-training: The main network and ReferenceNet learn the character features from single-frame images. Video Training: Introduces temporal modules and audio layers to process consecutive frame data, ensuring the dynamic effects of the video. Speed Layer Integration: Focuses on training the temporal modules and speed layers to optimize the ability of the audio to drive the character movements.
8. Video Generation
In the inference stage, the system uses the DDIM sampling algorithm to gradually generate video clips. Through multiple iterations of denoising, a high-quality portrait video synchronized with the input audio is finally outputted.